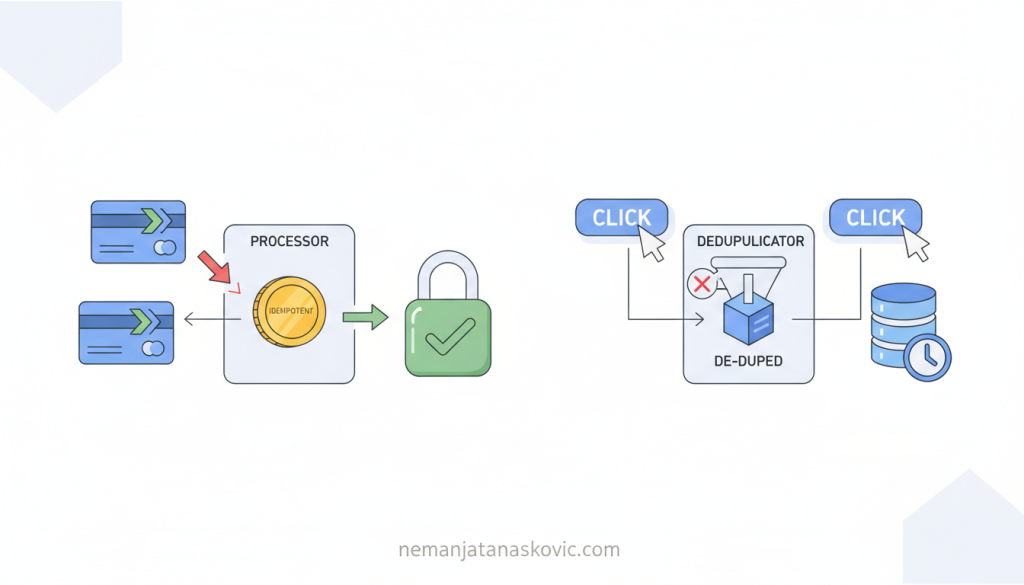

What happens when a payment API receives the same request twice—once due to a network hiccup, and again because a user impatiently clicks the button a second time?
This is where the concepts of idempotency and deduplication step into the spotlight. Both are crucial for building robust, reliable systems, but they’re often misunderstood or used interchangeably. In reality, idempotency and deduplication solve different problems, each with its own set of trade-offs, implementation patterns, and best-use scenarios.
Let’s roll up our sleeves and break down idempotency vs deduplication, using real-world examples, analogies, and practical code snippets. By the end, you’ll know exactly when to reach for each tool—and how to avoid the subtle bugs that can sneak in if you get them mixed up.
Why the Distinction Matters: A Real-World Scenario
Picture this: you’re building an online food delivery app. A customer places an order, but their internet connection is spotty. The app resends the order request, just to be safe. Suddenly, the kitchen receives two identical orders for the same pizza. Chaos (and extra cheese) ensues.
Was this a failure of idempotency, deduplication, or both? Understanding the difference isn’t just academic—it’s the key to preventing double charges, duplicate emails, and all sorts of user headaches.
Idempotency: The Power of Predictable Repeats
Let’s start with idempotency. In plain English, an operation is idempotent if performing it multiple times has the same effect as performing it once. No matter how many times you hit the button, the outcome doesn’t change after the first successful execution.
The Classic Example: HTTP Methods
- GET requests are naturally idempotent. Fetching your profile page 10 times doesn’t change your data.
- PUT is designed to be idempotent. Setting your shipping address to “123 Main St” repeatedly always results in the same address.
- POST is not idempotent by default. Submitting a payment form twice might charge your card twice—unless you build in idempotency.
Why Idempotency Matters
Idempotency is your shield against accidental repeats caused by network retries, user impatience, or system glitches. It’s especially vital in distributed systems, where messages can be delayed, duplicated, or delivered out of order.
Analogy: The Light Switch
Think of idempotency like a light switch. Flipping the switch to “on” once turns on the light. Flipping it to “on” again doesn’t make the room any brighter. The state is already set.
Implementing Idempotency: The Idempotency Key
A common pattern is to require clients to send a unique idempotency key with each request. The server stores the result of the first request for that key and returns the same result for any subsequent requests with the same key.
Example: Payment API (Python-style pseudocode)
# Pseudocode for idempotent payment processing
def process_payment(request):
idempotency_key = request.headers['Idempotency-Key']
if idempotency_key in processed_requests:
return processed_requests[idempotency_key]
result = actually_charge_card(request.data)
processed_requests[idempotency_key] = result
return result
- The first request with a new key processes the payment.
- Any repeat with the same key just returns the stored result—no double charge.
When to Use Idempotency
- Financial transactions (payments, refunds)
- Resource creation (user signups, order placement)
- APIs that may receive retries
Idempotency is about making repeated operations safe, not about preventing duplicates from ever being created. That’s where deduplication comes in.
Deduplication: The Art of Spotting and Removing Duplicates
Deduplication is all about identifying and eliminating duplicate data or requests. Unlike idempotency, which focuses on making operations safe to repeat, deduplication is about cleaning up after the fact—or preventing duplicates from being processed in the first place.
The Classic Example: Email Delivery
Imagine a newsletter system that, due to a bug, tries to send the same email to the same user multiple times. Deduplication logic can detect that the email has already been sent and skip the extra sends.
Analogy: The Mailroom
Picture a mailroom clerk sorting letters. If two identical letters to the same recipient show up, the clerk can toss one in the recycling bin. That’s deduplication in action.
Deduplication in Practice
Deduplication can happen at various stages:
– At the source: Preventing duplicate requests from being sent.
– In transit: Network layers or message brokers (like Kafka) can filter out duplicates.
– At the destination: The application checks for duplicates before processing.
Example: Message Queue Deduplication (Java-style pseudocode)
// Pseudocode for deduplicating messages in a queue
public void processMessage(Message msg) {
if (processedMessageIds.contains(msg.getId())) {
// Duplicate detected, skip processing
return;
}
handleBusinessLogic(msg);
processedMessageIds.add(msg.getId());
}
- Each message has a unique ID.
- If the ID has already been processed, the message is ignored.
When to Use Deduplication
- Email or notification systems
- Data import pipelines
- Message queues and event-driven architectures
- Database migrations or ETL jobs
Deduplication is about detecting and removing duplicates, not about making operations safe to repeat. That’s the key difference from idempotency.
Idempotency vs Deduplication: Head-to-Head Comparison
Let’s put these two concepts side by side to see how they stack up.
| Feature | Idempotency | Deduplication |
|---|---|---|
| Goal | Make repeated operations safe | Remove or ignore duplicate data/requests |
| Where applied | At the operation/endpoint level | At the data/message level |
| Typical use case | Payment APIs, resource creation | Email delivery, message queues, data imports |
| How it works | Returns same result for same input | Detects and skips/removes duplicates |
| Client involvement | Often requires client to send idempotency key | Usually transparent to client |
| State required? | Yes (store results by key) | Yes (track processed IDs or hashes) |
| Prevents side effects? | Yes | Only if duplicates are detected in time |
Key Takeaway
- Idempotency is about making operations safe to repeat.
- Deduplication is about removing or ignoring duplicates.
They often work together, but they’re not the same thing.
Real-World Case Studies: When to Use Which (or Both)
Let’s walk through a few scenarios to see how idempotency vs deduplication plays out in practice.
1. Payment Processing: The Double-Click Dilemma
A user clicks “Pay Now” twice. The backend receives two identical payment requests.
- Idempotency ensures that only one payment is processed, even if the request is received multiple times.
- Deduplication might be used at the message queue level to ensure only one payment event is processed downstream.
Best Practice: Use both. Idempotency at the API layer, deduplication in the event pipeline.
2. Email Campaigns: The Newsletter Nightmare
A bug causes the same email to be queued twice for the same user.
- Idempotency isn’t usually relevant here, since sending an email is not idempotent (sending twice means two emails).
- Deduplication is essential—check if the email has already been sent to the user before sending again.
Best Practice: Deduplication is your friend.
3. Data Import Pipelines: The CSV Conundrum
A CSV file is imported twice by mistake, leading to duplicate rows in the database.
- Idempotency could be built into the import operation (e.g., upsert instead of insert).
- Deduplication can be used to scan for and remove duplicate rows after import.
Best Practice: Use idempotent operations where possible, and deduplicate as a safety net.
4. RESTful APIs: Resource Creation
A client POSTs a new user registration twice due to a timeout.
- Idempotency (via idempotency key) ensures only one user is created.
- Deduplication could be used to scan for duplicate users (e.g., same email) as a backup.
Best Practice: Prioritize idempotency, but consider deduplication for extra safety.
How to Implement Idempotency: Patterns and Pitfalls
Idempotency isn’t magic—it requires careful design. Here’s how to do it right.
1. Idempotency Keys
Ask clients to generate a unique key for each logical operation. Store the result of the first request for that key, and return it for repeats.
- Where to store? In-memory cache (for short-lived keys), database (for long-term tracking), or distributed cache (like Redis).
- How long to keep keys? Depends on your use case—minutes for payments, days for resource creation.
2. Natural Idempotency
Some operations are naturally idempotent. For example, setting a user’s email to a specific value is idempotent—no matter how many times you do it, the result is the same.
3. Upserts (Update or Insert)
Instead of blindly inserting new records, use upserts to update existing records or insert if not present. This makes the operation idempotent.
Example: SQL Upsert
INSERT INTO users (email, name)
VALUES ('alice@example.com', 'Alice')
ON CONFLICT (email) DO UPDATE SET name = EXCLUDED.name;
- If the email exists, update the name.
- If not, insert a new row.
4. Handling Side Effects
Be careful with operations that have side effects (like sending emails or charging cards). Make sure side effects only happen once per idempotency key.
5. Error Handling
If an operation fails partway through, make sure retries don’t cause inconsistent state. Store enough information to detect partial completions.
How to Implement Deduplication: Strategies and Gotchas
Deduplication can be simple or complex, depending on your needs.
1. Unique Constraints
At the database level, use unique constraints to prevent duplicate records.
Example: Unique Email Constraint
CREATE TABLE users (
id SERIAL PRIMARY KEY,
email TEXT UNIQUE,
name TEXT
);
- The database will reject any attempt to insert a duplicate email.
2. Hashing and Checksums
For large data sets, compute a hash or checksum of each record. If a hash already exists, skip or merge the record.
3. Message Deduplication
In message queues (like Kafka, RabbitMQ, or AWS SQS), track message IDs or use deduplication features to avoid processing the same message twice.
4. Application-Level Deduplication
Keep a cache or database table of processed IDs. Before processing a new request, check if the ID has already been handled.
5. Periodic Cleanup
For data that accumulates over time, run periodic jobs to scan for and remove duplicates.
Common Pitfalls: Where Things Go Wrong
Even with the best intentions, it’s easy to trip up when implementing idempotency or deduplication.
1. Not Storing Enough State
Idempotency requires tracking the outcome of each operation by key. If you don’t store the result, you can’t safely return it for repeats.
2. Race Conditions
If two requests with the same idempotency key arrive at the same time, you might process both before the result is stored. Use database transactions or locks to prevent this.
3. Leaky Deduplication
If your deduplication logic only checks for exact matches, subtle differences (like whitespace or case) can slip through. Normalize data before comparing.
4. Overlapping Concerns
Sometimes, teams try to use idempotency when they really need deduplication, or vice versa. Be clear about your goals: are you making operations safe to repeat, or are you cleaning up duplicates?
Advanced Topics: Combining Idempotency and Deduplication
In complex systems, you’ll often need both idempotency and deduplication working together.
Example: Distributed Event Processing
Imagine a microservices architecture where events are published to a message bus. Each service needs to:
– Process each event exactly once (deduplication)
– Make sure processing is safe to retry (idempotency)
This is known as exactly-once processing—a notoriously tricky problem. Most systems settle for at-least-once delivery with idempotent handlers and deduplication logic.
Practical Tips
- Use idempotency keys for API endpoints.
- Track processed event IDs in a database or cache.
- Design handlers to be safe to repeat.
- Accept that some duplicates may slip through, and clean them up periodically.
Idempotency vs Deduplication in Popular Frameworks and Tools
Let’s see how these concepts show up in real-world tech stacks.
1. AWS SQS (Simple Queue Service)
- Deduplication: SQS FIFO queues support message deduplication using a deduplication ID.
- Idempotency: You still need to make your message handlers idempotent, since SQS guarantees at-least-once delivery.
2. Stripe API
- Idempotency: Stripe requires an idempotency key for payment requests, ensuring no double charges.
- Deduplication: Stripe’s webhooks can deliver the same event multiple times, so your webhook handler should deduplicate events by event ID.
3. Databases
- Deduplication: Unique constraints, upserts, and periodic cleanup jobs.
- Idempotency: Upserts and conditional updates.
4. Email Services (e.g., SendGrid, Mailgun)
- Deduplication: Track sent emails by recipient and campaign ID to avoid duplicates.
- Idempotency: Not usually relevant, since sending an email is not idempotent.
Practical Guidelines: Choosing the Right Tool
When you’re faced with a reliability problem, ask yourself:
- Is it safe to repeat this operation?
- If not, make it idempotent.
- Can duplicates sneak in?
- If so, add deduplication.
- Do I need both?
- In distributed systems, the answer is often yes.
Checklist for Idempotency
- Does the client send a unique key per operation?
- Is the result stored and returned for repeats?
- Are side effects (like emails or charges) only triggered once?
Checklist for Deduplication
- Are unique constraints in place?
- Is there a way to detect and skip duplicates?
- Are periodic cleanup jobs scheduled?
Wrapping Up: Idempotency vs Deduplication in the Real World
Idempotency vs deduplication isn’t a battle—it’s a partnership. Each tackles a different aspect of reliability:
– Idempotency makes operations safe to repeat, shielding you from accidental retries and network gremlins.
– Deduplication hunts down and eliminates duplicates, keeping your data and user experience clean.
In practice, robust systems often use both. Payments, emails, data imports, and distributed event processing all benefit from a thoughtful blend of idempotency and deduplication.
If you’re designing APIs, building data pipelines, or wrangling distributed systems, keep these concepts in your toolkit. And remember: a little extra effort up front can save you (and your users) from a world of confusion, double charges, and pizza-related mayhem.
Curious to see how these ideas play out in other programming patterns? Check out my deep dive on Java Interface vs Abstract Class: The Ultimate Guide for Developers for more on designing robust, flexible systems.
Happy coding—and may your operations always be idempotent, and your data always duplicate-free!